

This is a summary of a remarkable 🌳 tree book, which presents a theory for and methods to accelerate expertise in real-world contexts. This summary is not comprehensive; it only covers some of the actionable theories and recommendations in the book and leaves out the considerable lit review and the book’s recommendations for future research directions. I’ll note that Accelerated Expertise is not written for the lay person — it is a book primarily written for organisational psychologists, training program designers and researchers employed in the US military. If you must read it — say because you want to put the ideas in the book to practice — my recommendation is to read Chapters 9-13 and skim everything else.
Accelerated Expertise is about ‘taking the concept of skill development to the limit’. This is not a book about pure theory; nor is this a book about deliberate practice in well-developed skill domains. No: this is a book that pushes the limits of two lesser-known learning theories, and in so doing have created successful accelerated training programs in messy, real-world military and industrial contexts.
In 2008 and 2009, the US Air Force Research Laboratory convened a series of working meetings on ‘accelerated expertise and facilitated retention’, and invited a number of Naturalistic Decision Making (NDM) researchers, expertise researchers, and military organisational psychologists to attend. I’m imagining that some folks in the Human Performance Wing of the Air Force, along with the DoD Accelerated Learning Technology Focus Team had noticed that a number of these researchers were able to create accelerated expertise training programs in industry and in various branches of the military; my guess is that they wanted to extract the underlying principles from those training programs.
The report that come out of those meetings became the precursor to Accelerated Expertise — which was prepared by Robert R. Hoffman, Paul Ward, Paul J. Feltovich, Lia DiBello, Stephen M. Fiore and Dee H. Andrews for the Department of Defence and published in 2016.
The book opens with the following motivation:
The impetus for this book was a tasking from the Defense Science and Technology Advisory Group (DSTAG), which is the top-level Science and Technology policy-making panel in the Department of Defense. They were concerned about the complex issues that faced US and Coalition Forces in the wars in Afghanistan and Iraq. Junior officers and enlisted personnel were facing missions and tasks that our military had not had to face since the war in Vietnam, tasks such as counter-insurgency warfare and temporarily governing villages. During the Cold War, military personnel could typically count on being assigned to one location for at least three years before rotating to the next. That era allowed for robust continuous training while at a duty station. However, in the current era of frequent deployments to a variety of locations worldwide to fight the War on Terror, there are far fewer opportunities to have systematic training and practice. These are highly dynamic tasks that require considerable cognitive flexibility. Speed in acquiring the knowledge and skills to perform the tasks is crucial, as the training must often be updated and provided shortly before the personnel must deploy to the theatres where the wars are being fought.
I include this motivation only because it provides context behind the training methods discussed here. As you’ll soon see, some of the methods in Accelerated Expertise violate certain educational principles found in more traditional classroom environments. Many of these methods were developed for industry and military contexts instead of in labs or in classrooms. Presumably this might limit some of their applications. But perhaps it might also make the ideas more attractive to you, assuming that you distrust — as I do — the effectiveness of classroom instruction.
Accelerated Expertise is divided into three parts. Part 1 presents a literature review of the entire expertise research landscape circa 2016. Part 2 presents several demonstrations of successful accelerated training programs, and then an underlying theory for why those training programs work so well. Part 2 also contains a generalised structure for creating these accelerated expertise training programs. Part 3 presents a research agenda for the future, and unifies Parts 1 and 2 by pointing out all the holes in the empirical base on which existing accelerated training programs have been built.
This summary will focus on Part 2. As you might expect, the ideas and recommendations in the book deviate from certain mainstream ideas about pedagogy and training. If you want to accelerate expertise, it stands to reason that you might want to do things differently from training methods that have come before.

What the Military Wanted
The military wanted two things:
- It wanted new training methods and learning technologies that could accelerate the achievement of high levels of proficiency. (Note: proficiency is different from expertise — we’ll return to this in a moment).
- It wanted high retention of knowledge and skill. This latter requirement was due to the organisational nature of the military — it is common for military personnel to be temporarily reassigned to administrative duty for a few years in the middle of active service. For example, an Air Force pilot might be reassigned to teaching duty at an academy for a year or two before returning to the field. The Department of Defence wanted to reduce the amount of retraining necessary to get these pilots up to speed. It tasked researchers to come up with new methods or new research agendas for these problems.
Over the course of the two meetings, it became clear that the requirements from the military could be broken down into four granular subgoals, all of which were important for both military and for industry applications:
- Methods to quicken the training process while maintaining its effectiveness (Rapidised Training).
- Methods to rapidise the transposition of lessons learnt from the battlespace into the training context — for instance, if insurgents evolve their tactics, there should be a way to rapidly integrate this ‘meta’ into existing training programs. (Rapidised Knowledge Sharing).
- Methods to train more quickly to higher levels of proficiency (Accelerated Proficiency) and
- Methods to insure that training has a stable and lasting effect (Facilitated Retention)
The training approach that they present in Part 2 of the book fulfil many of the four requirements above.
The reason there is a difference between ‘proficiency’ and ‘expertise’ is that the authors do not know if it is possible to accelerate ‘high proficiency’ (sometimes called ‘mastery’, or ‘expertise’). In their report, the authors write:
The goal of accelerated learning calls out an important practical tension. On the one hand is the notion that we must accelerate learning; that is, increase the rate at which highly proficient performance is achieved. On the other hand, there is a significant amount of evidence that developing expertise requires up to 10 years of experience, including practice at tough tasks (Hoffman, 1998). This suggests that it is not possible to accelerate the achievement of high proficiency. A prime goal of the DoD Accelerated Learning Technology Focus Team is to identify critical research challenges that are currently underfunded or not funded, and generate a notional roadmap for science and technology advancement.
They conclude, tentatively, that perhaps it is only possible to accelerate proficiency between senior apprentice and junior journeyman levels (or between senior journeyman and junior expert levels). They present the following stylised growth curve:
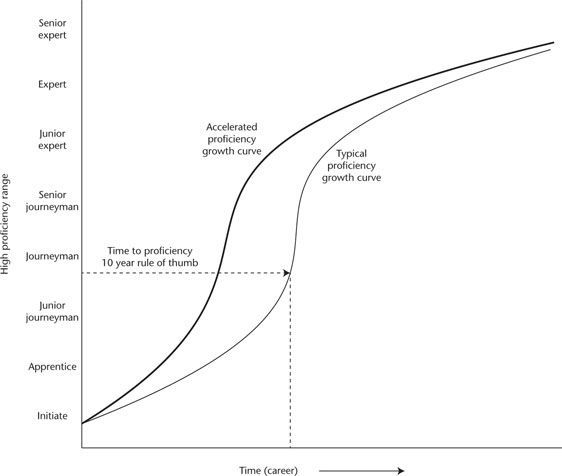
Perhaps, the authors say, overall mastery still takes 10 years in the field, and there’s nothing we can do about that.
But what we do know is this: the set of successful accelerated training programs that currently exist enable accelerated proficiency, not accelerated mastery.
And perhaps that is good enough!
How to Accelerate Expertise?
Let’s consider the problem from first principles.
Let’s pretend that you are a training program designer. You need to get a bunch of novices to competency in a short amount of time. What would you do?
I think most of us would first ask: what is the skill tree for this domain? We would attempt to figure out a set of atomised skills and lay them out from the most basic skills to the most advanced, and then design a training syllabus to teach each skill in the right order, making sure to teach the pre-requisites first, and then incrementally complexify our taught concepts and skills and training programs. We would probably also design exercises for the lower levels of skills, and attempt to create intermediate assessment tasks or ‘tests’.
We would, in short, attempt to replicate how we are taught in school.
The researchers say: No. Stop. Screw all of that.
There are a number of problems with this training approach. You might be familiar with some of them.
- First, this approach to training just takes too damn long. It is, after all, the mainstream approach to pedagogy, and it is this very paradigm that the researchers were asked to improve. A more interesting question is why it takes too damn long.
- There are two answers to this question. First, humans learn by constructing mental models of a domain. In the beginning, these mental models are crude and do not result in effective action. So novices evolve them rapidly by constructing, discarding, and re-constructing mental models in response to feedback. At some point, however, these mental models become effective enough and complex enough that they become knowledge shields — that is, mental models of a domain that are wrong in subtle ways, that prevent students from reaching higher levels of expertise because they enable them to reject anomalous data. In other words, breaking a skill domain down to atomised skills is risky — it is likely that you will accidentally cause the construction of subtly wrong mental models, due to the incomplete nature of a skill hierarchy. This then slows expertise development, since trainers would now have to do additional work — for instance, you would have to design your training tasks to include ‘knowledge shield destruction’ as a pedagogical goal. Better to avoid this completely.
- Breaking a skill domain down into a discrete learning hierarchy is bad for one other reason: experts are able to see connections and draw links between concepts or cues that novices cannot. Teaching atomised concepts will prevent novices from learning these connections, and may in fact result in either subpar performance or a training plateau later on. (Note: this is not a universal recommendation; the authors note that The Simplifying Conditions Method, as demonstrated by Kim & Reigeluth is one way to break a domain down while emphasising connections between concepts, but this pedagogical method is not universally known. Better to do without this requirement altogether).
- The second reason a hierarchical training approach sucks is that assessments for atomised skills do not translate to assessments of real world performance. I think we know this intuitively. Tests for basic skills often do not capture the nuances of skill application in real world environments. You can test well in corporate finance and then run a company to the ground, because you do not know what cues to look for in the particular business you’re in.
- The third reason this training approach sucks is that atomised training often does not have high cognitive fidelity to the context of use. Take, for instance, ‘Cognitive Load Theory’. This is a famous theory of classroom learning, and it basically says that ‘intrinsic cognitive load’ is related to the complexity of the learning task itself; ‘extraneous cognitive load’ is caused by activities during learning that are unnecessary and interfere with schema acquisition. The teacher’s job is to design teaching methods that reduce extraneous cognitive load. The authors point out that this is all well and good when your student needs to take a test, but if your work environment involves bombs dropping on you while you plan your troop movements, perhaps your training program should also include some ‘extraneous cognitive load’?
- The fourth reason this training approach sucks is that it is not easy to update the training program if the skill domain changes. This is an important requirement in both business and in military contexts — you might imagine that if the market environment changes (in business), or if insurgents evolve their IED tactics, you would need to quickly update your training program. But a hierarchical syllabus resists updating. Which lesson do you update? At what level of complexity? What pre-requisites must change? There are too many moving parts. It should be easier to update training. Meanwhile, soldiers get deployed to the frontlines without updated training and die.
- The fifth reason this training approach sucks is that external assessments often degrade the learner’s ability to sensemake in the field. In other words, extremely clear feedback sometimes prevents students from learning effectively from experience, which may slow their learning when they arrive in a real world domain.
So what do you do? What do you do if you can’t design a hierarchical skill tree? What do you do if incremental complexification is off the table?
The answer: you cheat.
I’ve talked about the Naturalistic Decision Making branch of psychology in the past. The NDM field contains methods to extract tacit mental models of expertise. These methods are loosely categorised under the name ‘cognitive task analysis’, or ‘CTA’, and have been developed over a 30 year period in applied domains. I’ve written about NDM in my tacit knowledge series, and I’ve written about ACTA, the simplest form of CTA here and here. I recommend that you read them both.
What CTA allows you to do is to extract the actual mental model of expertise that experts have in their heads. This allows you to sidestep the problem of good hierarchical skill tree design. Once you have an explicated mental model of the expertise you desire, you may ask a simpler question: what kind of simulations may I design to provoke the construction of those mental models in the heads of my students?
This core insight underpins many of the successful accelerated expertise training programs in use today.
With that in mind, this is the general structure of an accelerated expertise training program, as recommended by the book:
- Identify who the domain experts are. The book gives you four methods for expert identification — (1) in depth career interviews about education, training and job experiences, (2) professional standards or licensing, (3) measures of actual performance at familiar tasks, and finally (4) social interaction analysis (asking groups of practitioners who is a master at what).
- Perform cognitive task analysis on these identified experts to extract their expertise. Depending on the exact CTA method you use, this step will initially take a few months, and require multiple interviews with multiple experts (and also with some novices) in order to perform good extraction.
- As you do step 2, you will be building a case library of difficult cases. Store these cases, and code them according to measures of difficulty. You may ask experts to help you with the coding.
- Next, turn your case library into a set of training simulations. This step is a bit of an art — the researchers say that ‘no set of generalised principles currently exist for designing a good simulation’. They know that cognitive fidelity to the real world is key — but how good must the fidelity be? Training programs here span from full virtual simulations (using VR headsets) to pen-and-paper decision making exercises (called Tactical Decision-making Games) employed by the Marines.
- Some training programs are designed so that learners are required to perform sensemaking on their own — that is, to introspect and reflect on what they’ve learnt from each simulation. Others include feedback from a more experienced practitioner, or one that has been identified as an ‘expert’ in step 1.
- Some training programs may present abstract or generalised principles up front, which are then emphasised through training simulation. For instance, the Marines have a heuristic for when battlefield plans break down: “keep moving, seek the high ground, stay in touch.” This is taught explicitly.
- Finally, test the program: run your learners through your set of training simulations, ranging from simple to difficult. This also requires some amount of tweaking — the authors note that ‘difficulty’ in a domain is complex, and it may take some trial and error to figure out a good ordering of cases, or a good categorisation scheme (more advanced learners should be assigned more difficult cases, or you risk constructing or reinforcing knowledge shields).
- Feedback in simulation training is sometimes qualitative and multi-factorial. Some exercises like Gary Klein’s Shadowbox method ask multiple-choice question at critical decision points during a presented scenario (e.g., ‘at this point of the cardiac arrest (freeze-frame the video), what cues do you consider important?’). Learners then compare their answers to an experts’s, and then reflect on what they missed. Other forms of feedback are less clear-cut. US Marine Tactical Decision-making Games are conducted on pen-and-paper in a group environment, with one or two more experienced commanders. Feedback is organic and emerges from the group discussion. Lia DiBello’s Strategic Rehearsals are performed in a group setting within the business, and simply give participants a list of three questions to discuss after a failed simulation: (1) what went wrong, (2) what we will do differently this time, and (3) how will we know it is working? Sometimes this is paired with a constructive exercise, facilitated by the trainers.
We’ll get into a real world example in a bit, but I want to call out a few remarkable things about this approach:
- Notice how case libraries and simulations may be easily updated. If the battlespace changes, training program designers that are proficient in CTA may be deployed to the frontlines to do skill extraction, and then return to turn those into additional training simulations.
- Skill retention is very compatible with this approach — experienced practitioners may be put on a spaced-repetition program where they do periodic training simulations. Alternatively, if the practitioner is not able to do training simulations (perhaps because they are assigned to a location that is too far away from a training facility), an alternative is to perform ‘over-training’ — that is, intensive simulation training right before he or she is reassigned, which results in a more gentle skill drop-off rate. There are two caveats to this: first, spaced repetition has mostly been shown to work for knowledge retention, not skill retention; second, in general, studies tell us that skills tend to be retained for a longer period than knowledge. The authors note that we currently lack a good empirical base for skill retention.
- Not doing basic skill training seems excessive — but the authors note that training simulations do not preclude teaching basic skills.
- A common reaction to this training approach is to say “wait, but novices will feel lost and overwhelmed if they have no basic conceptual training and are instead thrown into real world tasks!” — and this is certainly a valid concern. To be fair, the book’s approach may be combined with some form of atomised skill training up front. But it’s worth asking if a novice’s feeling of artificial progression is actually helpful, if the progression comes at the expense of real world performance. The authors basically shrug this off and say (I’m paraphrasing): “well, do you want accelerated expertise or not?” In more formal learning science terms, this ‘overwhelming’ feeling is probably best seen as a ‘desirable difficulty’, and may be an acceptable price to pay for acceleration.
- I’ve noticed that sensemaking plays a key part in many of their training programs. Simulation training gives trainers the option of asking students to perform — and therefore learn from — sensemaking, instead of seeking explicit feedback. This is not always doable, but is generally a good idea, since skill mastery in real world domains emerges from effective reflection. As such, many training programs guide learners to reflect on dynamic, messy feedback.
There are many other interesting ideas that I cannot get into, for the sake of brevity. For instance, one fascinating comment, presented in Chapter 14, is the idea that case libraries may serve as the basis of ‘organisational knowledge management’:
Case experience is so important to the achievement of proficiency that it can be assumed that organisations would need very large case repositories for use in training (and also to preserve organisational memory). Instruction using cases is greatly enhanced when “just the right case” or set of cases can be engaged at a prime learning moment for a learner (Kolodner, 1993). This also argues for a need for large numbers of cases, to cover many contingencies. Creating and maintaining case libraries is a matter of organisation among cases, good retrieval schemes, and smart indexing—all so that “lessons learned” do not become “lessons forgotten.”
The US Marines, for instance, own a large and growing library of ‘Tactical Decision-Making Games’, or ‘TDGs’, built from various real or virtual battlefield scenarios; these represent a corpus of the collective operational expertise of the Marines Corps.

The authors note that this isn’t limited to military applications. Take, for instance, the domain of power generation, where one of the authors was tasked with a project on capturing tacit expertise in a retiring workforce:
It is easy to acquire and instil “middle of the bell curve” knowledge (in an electric utilities company), but at an electric plant there will be, say, five out of 1500 people who are irreplaceable. When (not if) the need arises, much effort is required to transpose high-end technical wisdom to a few specified individuals who are mission-critical in that their value lies at the fringes of some particular discipline (e.g., individuals who keep the company out of the newspaper; individuals who make sure the lights do not go out at Giant Stadium on Monday night). The high-end or “franchise experts” sometimes change the mission and thereby make the total organization resilient (Hoffman et al., 2011). For example, when a fire started in a relay station building that had lots of asbestos, the expert’s novel solution was to seal off the building, flush the insides into one single storm drain and grab the debris from there. The process took a couple of weeks (vs. many weeks), it protected the public and the environment, and it kept the incident out of the newspapers.
While expertise may be acquired in around 10 years, typically it takes 25-35 years to achieve very high-end proficiency. This is related, in part, not just to the frequency of meaningful real-world experiences that could be leveraged to further skill acquisition, but to the complexity of the domain and the longevity of the technology. (For instance, only recently have utilities begun the change from analog controls to digital controls.) Many stories are told of the engineering challenges in New York City. Engineers have to maintain and integrate numerous subsystems built in different eras. A senior relay system protection engineer retired, and was replaced by four engineers, each having had 10 years of experience. That did not suffice. (emphasis added) When a car hit a pole and two lines tripped, both lines were lost. Across the two lines there were dozens of different kinds of relays and dozens of different kinds of relay protection schemes, some 50 years old. The retired engineer had to be brought back in to fix this emergency situation.
In other words, what serves as a difficult case library for training may also double as a store of expertise.
Case Study: IED Defeat
Let’s look at an example of a single accelerated expertise training program. I’ve mentioned this story before, in my post about NDM training methods, but I’m retelling it here because I think the story is a good one, and I think it illustrates the general approach pretty well.
(Note: Commonplace members may also read a summary of every published Strategic Rehearsal here. The Strategic Rehearsal or OpSim is an accelerated expertise training intervention developed by Lia DiBello, mostly used in the context of accelerating business expertise. It serves as a useful instantiation of the approach described above).
IED stands for ‘improvised explosive device’. Not long after 9/11, the US military began to have trouble with roadside bombs — what we now call IEDs — in both Iraq and Afghanistan.

The Department of Defence began throwing a lot of money at technology to detect and defeat IEDs. They invested in things like better protection and better armour in the vehicles to protect Warfighters, and created something called the Joint IED Defeat Organization (JIEDDO) to develop tactics to stem the loss of life from IEDs. As part of this research program, they also began looking into the human expertise element of detecting and defeating these devices. The DoD commissioned a handful of NDM researchers to extract expertise from Marines and Soldiers who appeared skilled at IED detection. The hope was that they would be able to design better training for novice Warfighters.
Before we continue with this story, let’s take a step back to consider this skill domain.
During our careers, you and I might be called to create training programs for our jobs. We might need to do so for computer programming, or for marketing, or for perhaps even hiring. None of these skill domains involve an adversary who is constantly evolving their tactics — much less evolving their tactics with the goal of killing us. And to make things worse, as the researchers started on their CTA interviews, they began to realise that IED tactics differed greatly from region to region. Even within Iraq, insurgents in different towns or different neighbourhoods had different tactics to emplace and trigger IEDs. And in Afghanistan it was different still.
The researchers had what seemed like an impossible task: they were asked to extract expertise from the heads of Warfighters who were adapted to local contexts. These Warfighters seemed to be able to ‘see the invisible’ — to recognise when things that should be there, weren’t there, to ‘get a bad feeling’ about certain zones … in other words, they were able to pick up cues in their local environment that nobody else seemed to pick up. But the researchers needed to extract something generalisable — something that could help a young Marine regardless of where they ended in their deployments.
In the end, the researchers realised that the most skilled Marines — the ones who were most successful at recognising a danger zone in advance — were able to put themselves in the adversary’s shoes. This, of course, sounds like an extremely obvious thing, but the nuance here is that the Marines were able to understand the constraints that these insurgents were working with.
Say, for instance, that you were an insurgent and that you wanted to place an IED — how would you do so, and how would you trigger it? If you used a wireless radio, then you would need to have a spotter located somewhere in the terrain to tell you where the Marines were located, and how close they were to the bomb. And to gauge that, you would need to set up some kind of spatial reference — in certain contexts, the insurgents would use a telephone pole, in other contexts they would build their own little rock formation on the road, in still other contexts they would use spray paint to mark some point on a wall. So the technique was the same — borne out of the constraints they had with their IED designs — but then the technique was implemented differently based on what was available in the particular environment.
Through some subtle adaptation process, these soldiers were picking up on these cues. They were able to think like insurgents.
Now imagine, for a moment, that you had reached this point. You had successfully performed your CTA extraction, and you now have an extracted mental model of IED defeat expertise. How would you go about teaching it to novice Marines?
The naive answer would be to set up a bunch of lectures on IED construction, emplacement, and trigger tactics, and then present scenario after scenario of IED cases to cohorts of young Soldiers. This would maybe make for an interesting presentation, with an afternoon of Powerpoint and note-taking. But it likely wouldn’t be very useful.
Here’s what the researchers did: they took an existing military video game called VBS, and then built out a module in the game where the Marines had to role-play as insurgents. Their in-game task: to emplace IEDs in the terrain. NDM researcher Jennifer Phillips said, of the training technology:
We were essentially putting them in a position where they had to think through how they were going to be effective in placing an IED. Whether they were going to use a cellphone detonator, or … with another sort of IED, they had to think through ‘When is the blue force convoy going to come through? What is the time of day right now? How can I disguise it? Where would be a good ambush zone?’ All of those kinds of considerations that are happening in the real world.
Now if you know VBS, you know that it’s got pretty good physical fidelity, but not great physical fidelity. So to your question about the cognitive fidelity really mattering … it didn’t matter that the physical video game environment was perfect or that the leaves on the trees were blowing in the wind exactly as they’re supposed to, what mattered was that we were putting the Marines in a position where they had to think through the problem from a different perspective, and that turned out to be very successful.

In the end, US Marines and Soldiers were required to play a few rounds of this game as part of their training, before deploying to Iraq or Afghanistan.
You can sort of squint and see all the aspects of the accelerated expertise training approach in this story:
- The researchers extracted expertise from the heads of experts in the field.
- As they were doing so, they turned the incidental scenario data into a case library.
- They turned that case library into a set of training simulations — by getting the soldiers to play as insurgents. In so doing, they facilitated the construction of a mental model that was similar to the original mental model of expertise identified in the field.
- This, in turn, resulted in a fairly short training cycle — the soldiers only had to play a few hours of the game to construct the right mental models.
- Presumably, if IED tactics evolved, they could probably update the game with new scenarios to reflect the nature of the battlespace.
This is what an accelerated expertise training program looks like.
The Underlying Theory
We’ll close with the underlying theory behind the training approach presented in Accelerated Expertise.
In Chapter 11, the authors assert that two core learning theories underpin their training approach, and may be combined:
- Cognitive Flexibility Theory, or CFT, and
- Cognitive Transformation Theory, or CTT
I’ve talked about CTT in the past, which you may read about here and here. This is the summary of both theories that the book presents:
Pertinent theories related to the acquisition and acceleration of expertise can be thought of as sets of hypotheses or postulates, which could be combined or merged, as we do in the following discussion of Cognitive Flexibility Theory (CFT) (Spiro et al., 1988, 1992) and Cognitive Transformation Theory (CTT) (Klein, 1997; Klein & Baxter, 2009). These two theories have the greatest relevance to empirical data collected on domains of cognitive work in the “real world.”
Because the two theories share the same core syllogisms, especially around mental model formation and knowledge shields, the researchers argue that they may both be combined. We'll take a look at how they do that in a bit.
Cognitive Flexibility Theory
Core syllogism
- 1) Learning is the active construction of conceptual understanding.
- 2) Training must support the learner in overcoming reductive explanation.
- 3) Reductive explanation reinforces and preserves itself through misconception networks and through knowledge shields.
- 4) Advanced learning is the ability to flexibly apply knowledge to cases within the domain.
- Therefore, instruction by incremental complexification will not be conducive of advanced learning.
- Therefore, advanced learning is promoted by emphasizing the interconnectedness of multiple cases and concepts along multiple dimensions, and the use of multiple, highly organized representations.
Empirical ground
- Studies of learning of topics that have conceptual complexity (medical students).
- Demonstrations of knowledge shields and dimensions of difficulty.
- Demonstrations that learners tend to oversimplify (reductive bias) by the spurious reduction of complexity.
- Studies of the value of using multiple analogies.
- Demonstrations that learners tend to regularise that which is irregular, which leads to failure to transfer knowledge to new cases.
- Demonstrations that learners tend to de-contextualize concepts, which leads to failure to transfer knowledge to new cases.
- Demonstrations that learners tend to take the role of passive recipient versus active participants.
- Hypothesis that learners tend to rely too much on generic abstractions, which can be too far removed from the specific instances experienced to be apparently applicable to new cases, i.e., failure to transfer knowledge to new cases.
- Conceptual complexity and case-to-case irregularity pose problems for traditional theories and modes of instruction.
- Instruction that simplifies and then complicates incrementally can detract from advanced knowledge acquisition by facilitating the formation of reductive understanding and knowledge shields.
- Instruction that emphasizes recall memory will not contribute to inferential understanding and advanced knowledge acquisition (transfer).
Additional propositions in the theory
- Advanced knowledge acquisition (apprentice-journeyman-expert) depends on the ability to achieve deeper understanding and apply it flexibly.
- Barriers to advanced learning include complexity, interactions, context-dependence, and illstructuredness (inconsistent patterns of concepts-in-combination).
- Cognitive flexibility includes the ability to mobilize small, pre-compiled knowledge structures, and this “adaptive schema assembly” involves integration and updating, rather than just recall.
- Active “assembly of knowledge” from different conceptual and case sources is more important in learning (for domains of complexity and ill-structuredness) than retrieval of knowledge structures.
- Misconceptions compound into networks of misconceptions. Misconceptions of fundamental concepts can cohere in systematic ways, making each misconception easier to believe and harder to change.
- Representations with high interconnectedness will tend to serve as “misconception-disabling correct knowledge.”
- Cognitive flexibility is the ability to represent knowledge from different conceptual and case perspectives and construct from those an adaptive knowledge ensemble tailored to the needs of the problem at hand.
Cognitive Transformation Theory
Core syllogism
- 1) Learning consists of the elaboration and replacement of mental models.
- 2) Mental models are limited and include knowledge shields.
- 3) Knowledge shields lead to wrong diagnoses and enable the discounting of evidence.
- Therefore learning must also involve unlearning.
Empirical ground and claims
- Studies of the reasoning of scientists
- Flawed “storehouse” memory metaphor and the teaching philosophy it entailed (memorization of facts; practice plus immediate feedback, outcome feedback).
- Studies of science learning showing how misconceptions lead to error.
- Studies of scientist and student reactions to anomalous data.
- Success of “cognitive conflict” methods at producing conceptual change.
Additional propositions in the theory
- Mental models are reductive and fragmented, and therefore incomplete and flawed.
- Learning is the refinement of mental models. Mental models provide causal explanations.
- Experts have more detailed and more sophisticated mental models than novices. Experts have more accurate causal mental models.
- Flawed mental models are barriers to learning (knowledge shields).
- Learning is by sensemaking (discovery, reflection) as well as by teaching.
- Refinement of mental models entails at least some un-learning (accommodation; restructuring, changes to core concepts).
- Refinement of mental models can take the form of increased sophistication of a flawed model, making it easier for the learner to explain away inconsistencies or anomalous data.
- Learning is discontinuous. (Learning advances when flawed mental models are replaced, and is stable when a model is refined and gets harder to disconfirm.)
- People have a variety of fragmented mental models. “Central” mental models are causal stories.
The emphasis of CFT is on overcoming simplifying mental models. Hence it advises against applying instructional methods that involve progressive complexity. CTT, on the other hand, focuses on strategies, and the learning and unlearning of strategies. The two theories focus on marginally different things:
CFT and CTT each try to achieve increases in proficiency, but in different ways. For CFT, it is flexibility and for CTT, it is a better mental model, but one that will have to be thrown out later on. CFT does not say what the sweet spot is for flexibility. A learner who over complexifies may not get any traction and might become paralysed. It thus might be considered a “lopsided” theory, or at least an incomplete one. CFT emphasises the achievement of flexibility whereas CTT emphasises the need for unlearning and relearning. Both theories regard advanced learning as a form of sensemaking (discovery, reflection) and both regard learning as discontinuous; advancing when flawed mental models are replaced, stable when a model is refined and gets harder to disconfirm.
I recommend reading through the two theories carefully, reflecting on their implications, and perhaps investigating their origins (the paper for CFT is here; the paper for CTT found here). The implications of both theories are quite profound, and are expressed in the training approach presented at the heart of Accelerated Expertise. But they may also be found in many of the training approaches found in the NDM world.
By the middle of Part 2 of the book, the two theories are combined into one core theory, like so:
The core syllogism of the CFT-CTT merger
- 1) Learning is the active construction of knowledge; the elaboration and replacement of mental models, causal stories, or conceptual understandings.
- 2) All mental models are limited. People have a variety of fragmentary and often reductive mental models.
- 3) Training must support the learner in overcoming reductive explanations.
- 4) Knowledge shields lead to wrong diagnoses and enable the discounting of evidence.
- 5) Reductive explanation reinforces and preserves itself through misconception networks and through knowledge shields. Flexible learning involves the interplay of concepts and contextual particulars as they play out within and are influenced by cases of application within a domain.
- Therefore learning must also involve unlearning and relearning.
- Therefore advanced learning is promoted by emphasising the interconnectedness of multiple cases and concepts along multiple conceptual dimensions, and the use of multiple, highly organised representations.
Other implications of this theory likely exist. I’m still working them out for myself, and I urge you to do the same.
Wrapping Up
I would be irresponsible if I didn’t mention the two biggest takeaways from the first half of the book. Over the course of seven chapters, the authors take great pain to repeat two lessons again and again:
- That, first, everything in the expertise literature is difficult to generalise. Some methods work well in some domains but not in others. The ultimate test is in the application: if you attempt to put something to practice, and it doesn’t work out, it doesn’t necessarily mean that the technique is bad. It just means that it doesn’t work for your particular context. The sooner you learn to embrace this, the better.
- Second, the authors take care to point out that a great many things about training can probably never be known. For instance, it is nearly impossible to isolate the factors that result in successful training in real world contexts — and yet real world contexts is ultimately where we want training to occur. There are simply too many confounding variables. And the truth is that we can’t go the other way and run perfectly controlled experiments either — there is a great deal of difficulty getting lab-based or classroom-based training to work. Certainly, the military (and industry!) is interested in what works on the battlefield and in the corporation; it doesn’t really care about what is publishable or testable in controlled classroom environments.
The overall picture that I got from the book goes something like this: “We know very little about expertise. There are large gaps in our empirical base. (Please, DoD, fund us so we can plug them!) What we do know is messy, because there are a ton of confounding variables. And yet, given that we’ve mostly worked in applied domains, our training programs seem to deliver results for businesses and soldiers, even if we don’t perfectly understand how they do so. Perhaps this is simply the nature of things in expertise research. We have discovered several things that work — the biggest of which is Cognitive Task Analysis, which enable us to extract actual mental models of expertise. We also have a usable macrocognitive theory of learning. But beyond that — phooey. Perhaps we just have to keep trying things, and check that our learners get better faster, and we can only speculate at why our programs work; we can never know for sure.”
This appears to be the price of research in real world environments. And I have to say: if the price of progress in expertise is that we don’t really know what works for sure, then I think on balance, this isn’t too bad. But I am a practitioner, not a scientist; I want things that work, I don’t necessarily need to get at the truth.
I can’t wait to put some of these ideas to practice. And I can’t wait to see what these researchers discover next.
Originally published , last updated .
This article is part of the Expertise Acceleration topic cluster. Read more from this topic here→
The thought of business school make you go ‘eww’?
You’re in good company.
9,000+ investors and operators read Commoncog to sharpen their business acumen ... WITHOUT going back to school.
Sign up for our newsletter and get a weekly dose of good business thinking (no BS guaranteed):



