

This is a summary of a 🌳 tree book on teaching computer programming to beginners. You should read the original book in addition to this summary as tree books are not easily summarised. Read more about book classifications here.
This summary of Greg Wilson’s Teaching Tech Together is going to be a little different from the other book summaries I’ve done on Commonplace. For starters, I’m not going to summarise the main topic of this book, which is a concise, complete, evidence-backed guide to teaching computer programming to beginners. Instead, I’m going to focus solely on the section of the book that covers how humans learn, how knowledge is acquired, and what self-learners can do to learn better. This makes up chapters two to five of the book.
If you’re interested in teaching computer programming you would do well to read the entire thing from cover to cover; every technique described within is backed by a summary of the pedagogical research, contextualised with notes from practice, and bookended with actionable suggestions and motivating examples. There are also chapters on community building, inclusiveness and diversity, giving feedback on teaching performance, practicing co-teaching with fellow teachers, and handling branding, marketing and partnerships if you are running a software course for the public and want to get the word out about your lessons.
To say this book is a tour de force is an understatement; nearly every technique, actionable recommendation and assertion is backed by citations to papers you may chase down to read. This is a wonderful book, and I think more people should know about it.
That said, I don’t believe many of my readers are interested in learning to teach programming. So let’s focus on the thing that will interest most of you: i.e.: what do we know about how humans learn? And how might we use that knowledge to learn better, as individuals?
How do Humans Learn?
Teaching Tech Together contains an extremely concise, practical overview of the cognitive psychology and learning science literature. It begins with a summary of the differences between novices, competent practitioners and experts:
- Novices don’t know what they don’t know — that is, they don’t yet have a usable mental model of the domain.
- Competent practitioners can do normal tasks with normal effort under normal circumstances because they have a mental model that’s good enough for everyday purposes. The model doesn’t have to be complete or accurate, just useful.
- Experts have mental models that include all the complexities and special cases that competent practitioners aren’t able to handle. This then allows them to handle situations that are out of the ordinary. It also allows them to quickly diagnose and solve problems.
The goal of teaching is to build expertise —that is, to turn a novice learner into a competent practitioner, and to help a competent practitioner build expertise in order to become an expert.
When it comes to novices, a bad way of doing this is to inundate the learner with facts. This doesn’t work because the novice learner has no mental model with which to organise all the facts you’re throwing at them. Wilson asserts that the way you teach novices is to help them construct the right mental models, so they have somewhere to put your facts.
Let’s quickly dive into the two highlighted words above. First, why construct? Why not absorb, or learn? If we use these other words, our sentence above changes subtly: we would say “the way you teach novices is to help them absorb the right mental models …” — which implies a unit of insight passing from teacher to student … like telepathy, or receiving an orb of light.
Wilson uses the word ‘construct’ because he is most influenced by Seymour Papert’s work on knowledge acquisition. Papert’s claim is that humans learn by ‘construction’ — that is, we build knowledge in an iterative, cumulative way, replacing old, flawed mental models with newer ones, or stacking concepts on top of what we already know.
This explains many observable things about learning. It helps explain why you can’t simply explain your intuition and hope that students understand you; it explains why you must generate lots of examples and explanations until it clicks — and what clicks for one person may be different from what clicks for another.
It explains assistant professor Brent Yorgey’s Monad Burrito phenomenon:
Unfortunately, there is a whole cottage industry of monad tutorials that get this wrong. To see what I mean, imagine the following scenario: Joe Haskeller is trying to learn about monads. After struggling to understand them for a week, looking at examples, writing code, reading things other people have written, he finally has an “aha!” moment: everything is suddenly clear, and Joe Understands Monads! What has really happened, of course, is that Joe’s brain has fit all the details together into a higher-level abstraction, a metaphor which Joe can use to get an intuitive grasp of monads; let us suppose that Joe’s metaphor is that Monads are Like Burritos. Here is where Joe badly misinterprets his own thought process: “Of course!” Joe thinks. “It’s all so simple now. The key to understanding monads is that they are Like Burritos. If only I had thought of this before!” The problem, of course, is that if Joe HAD thought of this before, it wouldn’t have helped: the week of struggling through details was a necessary and integral part of forming Joe’s Burrito intuition, not a sad consequence of his failure to hit upon the idea sooner.
This constructivist understanding of learning means that any exercise of teaching is not so much a gift of knowledge from teacher to student — insight leaping from master’s brain to learner’s! — but is instead a guided walk as the teacher gently nudges the student based on whatever models the student currently holds in their heads.
Now, let us consider: what is a mental model? Wilson defines a mental model as:
… a simplified representation of the most important parts of some problem domain that is good enough to enable problem solving. One example is the ball-and-spring models of molecules used in high school chemistry. Atoms aren’t actually balls, and their bonds aren’t actually springs, but the model does a good job of helping people reason about chemical compounds and their reactions.
One important nuance of teaching is that it’s necessary to clear away broken mental models that are formed during the process of knowledge construction. Because novice learners build knowledge based on what they already know, it is very common for them to construct a mistaken mental model as they begin to progress in their learning. Good teachers watch out for this and clear it out; one important way they do this is to use formative assessments (formative here means ‘to form’, or ‘to shape’ the learning) to diagnose mistaken mental models. A good example follows:
… imagine that you have placed a block of ice in a bathtub and then filled the tub to the rim with water. When the ice melts, does the water level go up (so that the tub overflows), go down, or stay the same?
The correct answer is that the level stays the same: the ice displaces its own weight in water, so it exactly fills the “hole” it has made when it melts. Figuring out why helps people build a model of the relationship between weight, volume, and density.

The quality of the formative assessment, then, is that it diagnoses mistaken models, and gives the learner the opportunity to correct them. Papert suggests that all of learning should be like this: that the education system should be reformed to encourage facilitation, not recitation.
For instance, if a learner is made to move through a series of formative examples that are designed to subtly shape his or her understanding, this learner will develop intuition far quicker and more enjoyably than if he or she was given a mathematical equation in a lecture (and expected to develop intuition from that equation).
The former practice teaches through knowledge acquisition; the latter practice stems from the belief that insight can be passed along wholesale. The sad truth is that the majority of our education systems teach in the latter manner; it’s up to us to create the generative examples ourselves.
Mental Models and Expertise
What are the difference between the mental models of novices, competent practitioners and experts?
To understand this, it helps to use an illustration. Imagine that knowledge is represented as a graph, where the nodes are facts and the linkages between facts are relationships:
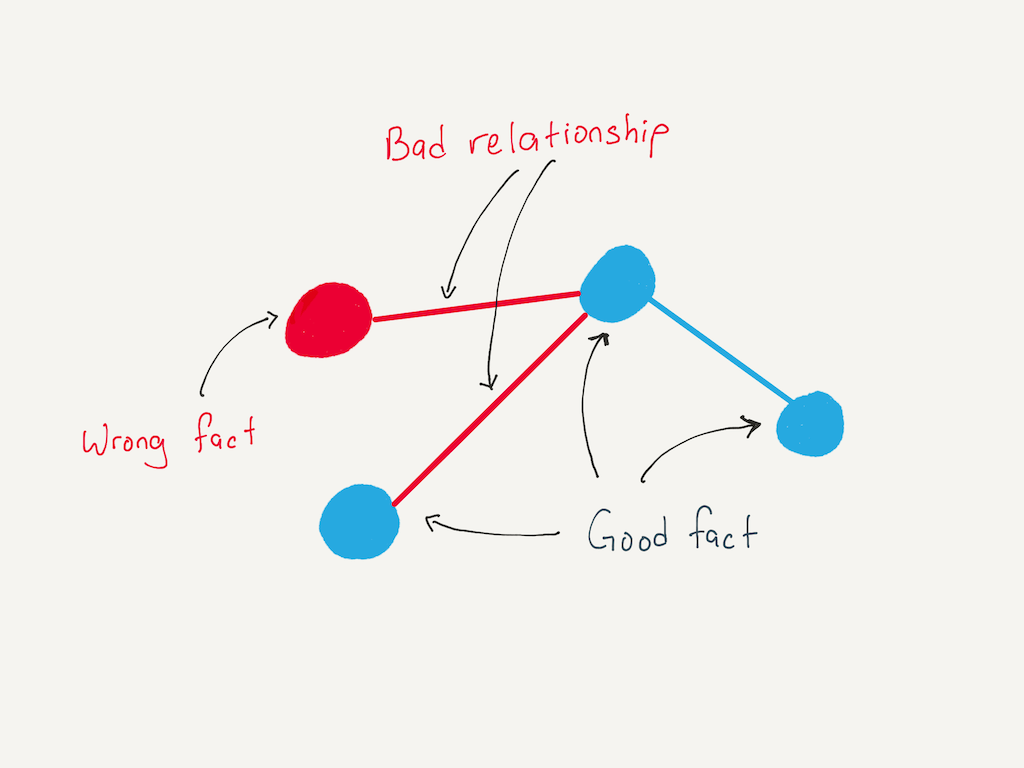
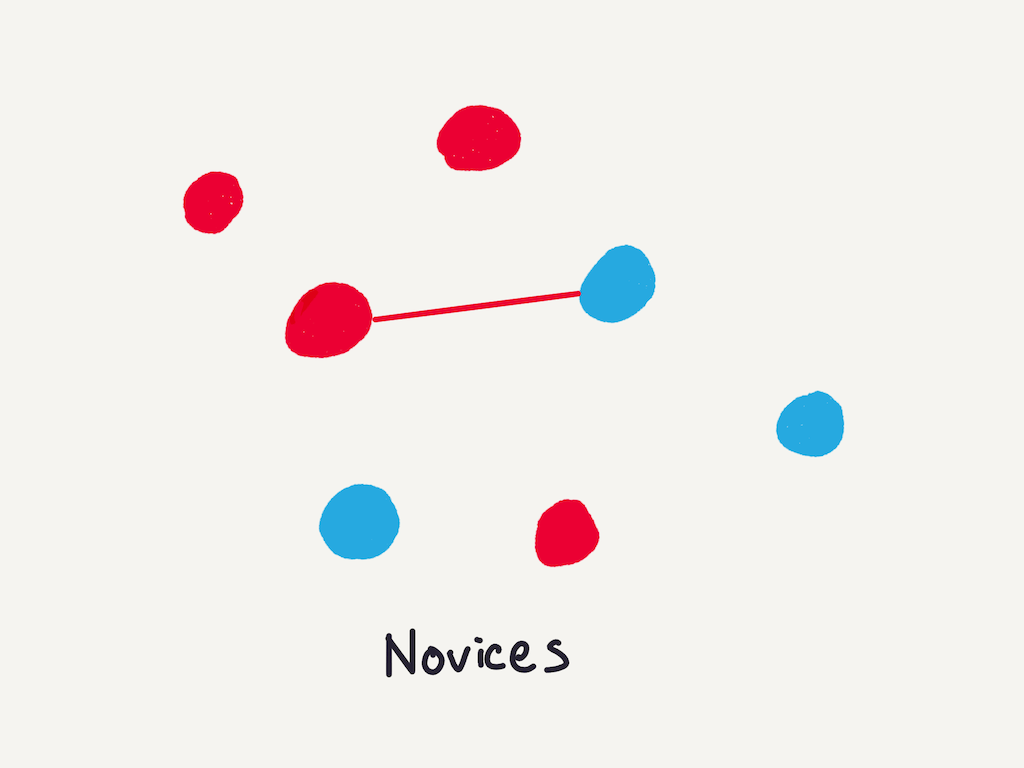
Novice start out with no facts or wrong facts, and no relationships (or mistaken relationships) between facts.
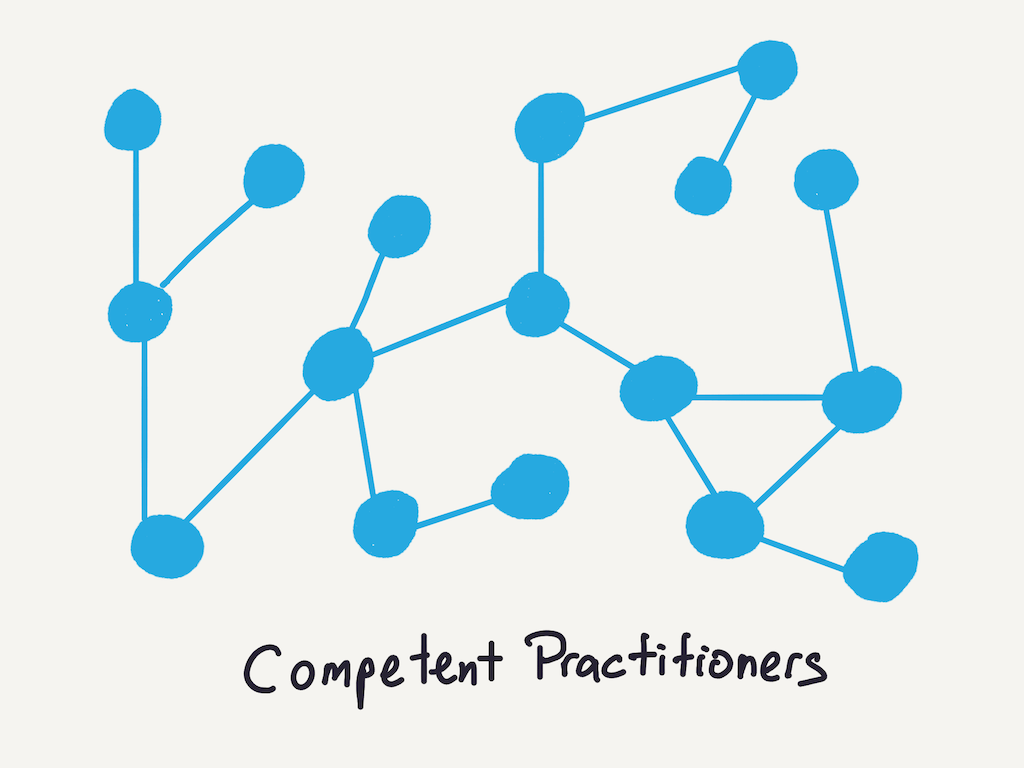
When Wilson says the job of teaching is to provide a mental model to slot facts in, he means that you should aim to provide a basic skeleton of linkages. Competent practitioners, for instance, have a basic mental model that’s good enough for use:
Experts — like competent practitioners, have a mental model and know how to organise new facts as they experience them; the primary difference is the density of relationships in their mental models of the domain.
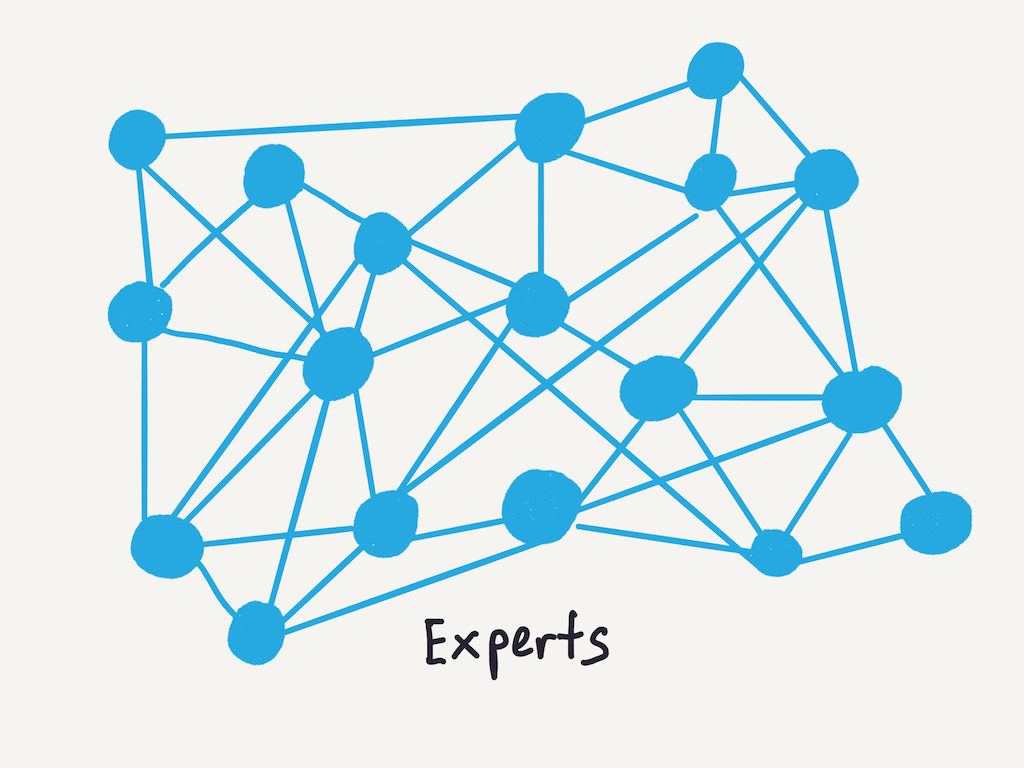
These densely connected mental models explains a bunch of observed aspects of expert behaviour:
- They can jump from a problem to solution without considering intermediate steps, because there is a direct link in their mind. For example, observing symptom E, an expert may immediately leap to root cause A; whereas a competent practitioner might need to reason E->D->C->B->A. We call this ‘intuition’, and it’s not necessarily good; experts are often unable to explain their reasoning.
- Experts are better at diagnosis than competent practitioners. More linkages means that experts find it easier to reason backwards from symptoms to causes. This is the main reason why asking programmers to debug during job interviews gives a more accurate impression of their ability than asking to program.
- Experts are often so familiar with the subject that they can no longer imagine what it’s like to not see the world that way. This is so pervasive that it has a name: ‘the expert blind spot’. The expert blind spot may be overcome by training, but it explains why experts are often less good at teaching the subject than people with less expertise who still remember learning it themselves.
Expertise, then, is a densely connected graph of facts. We should note that expertise comes not from the facts that are known (a competent practitioner may add many more facts to their mental model of the domain but not see an increase in expertise) — instead, expertise comes from how densely these facts are interconnected. And that interconnectedness comes from reflection and practice.
Concept Maps
This notion of ‘mental models as graphs’ aren’t just nice illustrations used to explain mental models. Wilson shows us that they’re also useful as teaching tools.
Wilson draws on research done at the Florida Institute for Human & Machine Cognition that illustrates that any subset of knowledge may be turned into something called a concept map. Here’s a concept map of why the Earth has seasons:

And here’s a concept map for for loops:

Concept maps are a form of externalised cognition — a thinking tool that makes thought processes and mental models visible so they can be compared, contrasted, and combined.
Wilson notes that concept maps are particularly useful in three different ways:
- When designing a lesson plan, teachers can draw concept maps while collaborating to understand differences in approach.
- Teachers can draw concept maps on a white board during teaching to make the connections and linkages explicit.
- Students can draw concept maps for teachers to check (as formative assessment). This activity is difficult for two reasons: first, it’s time consuming, so it cannot be done often, and second, concept map creation is a skill that must be taught before it can be used effectively.
It’s worth noting that concept maps should look as ugly and as ad-hoc as possible if you intend to use them as a collaborative tool — people are more likely to give honest feedback on something they think took only a few minutes to create.
(For more information on concept maps and to learn how to use them in your personal learning, go to IHMC’s concept maps page; note that concept maps are not mind maps.)
Concept maps are also interesting because — like most externalised cognition tools — they may be combined with insights into working memory to create better lesson design plans.
Working memory and 7±2
Human memory is divided into two parts: long-term memory and short-term memory. Long-term memory holds things like friend’s names, your home address, the memory of your first kiss — this type of memory is unbounded but slow to access.
Short-term memory, on the other hand, is much faster, but smaller: 7±2 is the number of discrete items you can hold in your head. This limit on short-term memory explains why phone numbers are typically seven or eight digits long; it also explains why professional sports teams are rarely more than nine people per function. (e.g. forwards and backs in rugby are half a dozen members; the idea here is that people’s ability to keep track of their peers is constrained by the size of working memory).
This insight is useful because you may use it for learning. During learning, a student cannot load new items directly into long-term memory. Instead, all learners load new information into their short-term memory. This new information is then transferred to long-term memory later, when it has been rehearsed and has sat in short-term memory for a long enough time.
This also means that a single teaching session should hold only 7 ± 2 total concepts. Wilson notes that he draws a concept map for each lesson he’s about to teach; if he finds that the number of concepts in his map exceeds this number, he splits the lesson into multiple parts, taking care to ensure that each lesson contains at most 7 ± 2 items.
How to become an expert
So what’s the upshot of all of this learning science? The short answer is: do deliberate practice. The 10,000 hours rule is cute but likely wrong; it’s probably better to optimise for this specific type of practice instead.
Deliberate practice is defined as doing similar but subtly different things, paying attention to what works and what doesn’t, and then changing behaviour in response to that feedback to get cumulatively better. (Sidenote: sounds like trial and error, doesn’t it?)
Wilson notes that a common progression is for people to act on feedback from others, then give feedback to others (to improve at this stage, it’s necessary for a teacher to critique their analysis), and then finally give feedback to themselves. A progression to this last stage is desirable because it is way more effective, as your feedback loop is much faster when you only have to deal with yourself.
I’ve covered the basics of deliberate practice elsewhere, particularly when summarising Cal Newport’s Deep Work — to be effective, deliberate practice requires a clear performance goal and immediate, informative feedback.
(I will note, though, that articulating the basics of deliberate practice is very different from actually trying to implement it; I’ll mark this down in my notes and chase it down in the near future.)
Individual Learning Strategies
Psychologists study learning in a wide variety of ways, but have reached similar conclusions about what actually works. (This is drawn from both cognitive and behavioural psychology; I quite like the idea that this convergence has happened — it hints that there’s maybe something deep and true about the nature of human learning).
Wilson points us helpfully to The Learning Scientists, who have collected six of those strategies and summarised them in a set of downloadable posters.
These six strategies are:
1. Spaced Practice
10 hours of study spaced out over five days is more effective than two five-hour days, and better than one 10-hour day. This is likely due to the nature of short-term memory and long-term memory; only so many things can be transferred to long-term memory at any given session.
Wilson suggests that individual learners make notes about things you’ve forgotten: that is, make a flash card for each fact that you couldn’t remember, or remembered incorrectly. That allows you to focus the next round on things that need most attention.
2. Retrieval Practice
Researchers now believe that the limiting factor for long-term memory is not retention (what is stored) but recall (what can be accessed). To put it simply: our brains fill up with junk, but nothing is ever truly forgotten; instead, we become unable to retrieve certain things. I guess evolution gave us the crappiest defragmenters possible.
The practical application of this idea is simple: when studying, use tests or exercises that force you to perform retrieval. For example, summarising details of a topic from memory and then checking to see what was and wasn’t remembered.
Another approach is to solve problems twice — the first time, do it entirely from memory without notes. Then after grading, solve the problem again with whatever resources you want. The difference between the two shows how well you were able to retrieve that knowledge.
The classic approach to retrieval practice is, of course, flash cards. In physical form, you write a question or prompt on one side of the card, and then write the answer on the other side. Wilson notes that there are also digital forms; and regardless of which you use, you may swap with study partners to see if you’ve missed or misunderstood important ideas.
3. Interleaving — interleave study of different topics.
Another way of spacing your practice is to interleave study of different topics, instead of mastering one subject at a time. Wilson points to research that show that switching up the order makes studying more effective: A-B-C-B-A-C is better than A-B-C-A-B-C, which in turn is better than A-A-B-B-C-C.
The reason this works is because interleaving creates more links between different topics, which in turn increases retention and recall.
4. Elaboration
Explaining things to yourself as you go through them helps you understand and remember them. Wilson means this literally: really do go talk to yourself!
One way to do this is to follow up each answer on a practice quiz with an explanation of why that answer is correct, or conversely with an explanation of why some other plausible answer isn’t. Another is to tell yourself how a new idea is similar to or different from one that you have seen previously.
Talking to yourself may seem like an odd way to study, but Biel1995 explicitly trained people in self-explanation, and yes, they outperformed those who hadn’t been trained. Go figure!
5. Concrete Examples
A special type of elaboration is so effective that it warrants its own section: generating concrete examples.
Whenever you see an abstract statement or a general principle, try to provide one or more examples of its use, or conversely take each particular problem and list the general principles it embodies.
Wilson points us to the ADEPT method, which is a structured way of generating concrete examples: give an Analogy, draw a Diagram, present an Example, describe the idea in Plain language, and then give the Technical details.
6. Dual Coding
The final technique draws on neurobiology. Because our brain processes and stores linguistic and visual information separately, it helps to combine words and images when you are studying in order to have the concepts reinforce each other. This works best when the textual and visual information are complementary without overlapping; for example: a diagram showing a timeline of events, and a written narrative right below it.
One concrete way to take advantage of this: draw a diagram and leave it unlabelled, and then come back later to label it as retrieval practice.
Fin
To be honest, this summary of Wilson’s book turned out a lot longer than I expected, and each learning technique or learning-science idea that I’ve covered here may well be expanded into individual blog posts.
I do intend to take each idea and apply them, though it’s probably going to be some time before I’ll be able to report back. I’m still working my way through a bunch of techniques I’ve learnt — in particular, I’m still practicing habit creation, and I’m applying the ideas from Just F*cking Ship to my next project.
But what Wilson’s covered in this tour de force is a remarkable starting point for anyone interested in teaching and learning better. The book is freely available online at this site, and you may download the ebooks for free at unglue.it. I highly recommend it.
Originally published , last updated .
This article is part of the Expertise Acceleration topic cluster. Read more from this topic here→
The thought of business school make you go ‘eww’?
You’re in good company.
9,000+ investors and operators read Commoncog to sharpen their business acumen ... WITHOUT going back to school.
Sign up for our newsletter and get a weekly dose of good business thinking (no BS guaranteed):



