

A reader asked me about memory retention strategies recently, in light of Andy Matuschak’s wonderful essay Why Books Don’t Work. I thought I would take some time to list down all the memory retention strategies I’ve experimented with over the past few years, along with links to all the relevant resources if you’d like to read more about them.
First, some context.
Matuschak’s essay makes a specific point, one that most of us should be familiar with. Books are — by themselves — terrible mediums to learn from. You can never score well in an exam by reading from a book alone. You do slightly better if you highlight while reading. You do better still if you summarise from memory at the end of every section. And you do best of all if you understand the ideas so deeply that you weave a web of interrelated concepts together.
(It’s a bit more complicated than that, but we’ll get to that in a bit).
I am interested in memory retention strategies in the context of building career moats. Building a career moat means building sustainable competitive advantages in one’s career — most of the time, this translates into acquiring rare and valuable skills.
Acquiring such skills demand that we learn to learn better. Memory retention strategies are an important component of this ability, which is why we're talking about them today.
Start From An Accurate Model
In order to understand and use memory retention techniques, we need an accurate model of human memory.
I have friends who think that human memory is like a hard disk drive: you have a finite amount of memory, and you occasionally need to consolidate and process fragmented blocks of data. This is partially correct: a psychologist friend tells me that the analogy of defragmentation actually maps pretty well to the work you do during Cognitive Behavioural Therapy, but the analogy otherwise falls apart.
Here’s a more useful model: human memory consists of two parts: short term memory and long term memory.
Short term memory is limited: you can only hold between five and nine items at any given time (this is sometimes presented as 7±2 — read as ‘seven plus or minus two’, or ‘Miller’s magical number’, and the paper that introduces it (Miller, 1956) remains one of the most highly cited papers in the whole of psychology).
In practice, it is better to think of this number as a heuristic — subsequent research suggests different numbers for chunked memory; 4±1, for instance, is the most commonly quoted alternative (Cowan 2001). There are also studies that propose differences in the storage capacity of words, letters, and numbers — but I’m leaving this out because the practical implication is the same: you can hold a limited number of chunked objects in your short term memory; the goal of learning is to transfer it to long term memory as effectively as possible.
While short term memory is fast but limited, long term memory is slow, but effectively infinite. The problem with long term memory is that of ‘accessibility, not availability’ — that is, you are not limited by space; you are limited by what you able to recall.
This implies that recalling strategies are at the core of learning. The brain recalls things in one of two ways: recognition — which is instantaneous and subconscious, and recall — which is explicit information retrieval (Gillund & Shiffrin, 1984). This is why it’s possible for you to recognise faces while forgetting names: facial recognition is recognition; name retrieval is recall … and the two operations use different subsystems in your brain.
This has a lot more implications than you think. The biggest implication comes when you discover that expertise is primarily built on recognition, not recall (Klein, 1999). Because recognition and recall operate using different subsystems in your brain, the kinds of techniques you use to build expertise must be different from the types of techniques you use to assist with recall. We’ll explore these implications in the second half of this essay.
One last thing: long term memory isn’t all the same. There are three types of knowledge that you store in long-term memory: episodic knowledge, declarative knowledge and procedural knowledge (Tulving, 1972, Cohen & Squire, 1980).
An example of episodic knowledge is ‘the horror of my first day of school’, or ‘that time when I peed my pants at the cinema’. It is usually vivid and primarily visual … though it can often be multi-sensory: in the example of the cinema incident, you are likely to remember your embarrassment, the smell of pee wafting from your pants, and the scratch of fabric in the cinema seat. (Eww).
An example of declarative knowledge is ‘Moscow is the capital of Russia’. This is what we normally associate with memory retention techniques.
An example of procedural knowledge is ‘how to ride a bike’. This type of knowledge is the basis of expertise.
Because our brain handles these three types of knowledge differently, using three different subsystems, learning techniques usually leverage one or more of these systems to aid recall. In fact, I’ll go so far as to say that mastery of learning is understanding which subsystem to use in service of which types of knowledge.
In the next couple of sections, I will cover techniques to assist with recall. Then I’ll cover techniques that assist with recognition. Both are necessary for the pursuit of expertise.
The normal principles of this blog apply: I’ll tell you if I’ve tested the ideas in my own life, and highlight the bits that I’ve not had much success with. Finally, I’ll tie it all together with a series of scenarios, which should cement these ideas for practical application in your life.
[Recall] The Mechanism of Remembering
What is the first principle of memory retention? It is this: you remember what you choose to recall.
Your brain is a ridiculously efficient piece of machinery. It refuses to spend energy storing things you won’t recall. The metric it uses to decide which information to store is the act of remembering itself — if you struggle to recall something, your brain takes note of it and strengthens the memory in question.
When I was a kid in Kuching, we used to memorise phone numbers. The most important set of phone numbers were my house landline, my mom’s cell phone number, and my dad’s cell phone number. Whenever we moved, or whenever my parents changed their cell phone numbers, I would notice that there would be a brief period of struggle to remember the new numbers before they reestablished themselves in my mind.
You’ve probably had similar experiences — think of creating a password for the first time, or using a new passport number. The more regularly you type in your new password, the more regularly you use your new passport, the more likely you would be able to recite these items from memory.
(Now, of course, we store our phone numbers, passwords, and ID numbers in our smart phones, and have no need to memorise.)
One implication of this is that the struggle is the goal of learning — that is, the uncomfortable feeling you get when you’re stretching to remember some formula or factoid is exactly what is necessary for information retrieval operations.
It also means that passively absorbing information during a lecture or while reading is less effective than actively questioning and engaging with the material being taught. The struggle to recall is the real reason testing and summarising strategies work: they force you to retrieve information you've just been exposed to.
(In fact, the testing effect is proof that recall should be a major goal of studying — a sizeable body of research has shown that even if you don’t give test takers feedback on their performance, memory retention still improves!)
But wait! Does this mean that the struggle to memorise is the goal of all study sessions? The answer is no, absolutely not. This goal is only valid when you’re attempting to learn declarative knowledge. For instance, if you're studying to be a doctor, you’ll need to memorise disease symptoms for clinical diagnosis. Or let’s say that you’re a student, and you are required to memorise your multiplication tables. In such situations, the struggle to recall is probably the most important aspect of studying. Many students attempt to ‘absorb’ knowledge by repeating a piece of information repeatedly to themselves. This is wrong, because it is not how the brain works. Instead, the goal should be the pain of recall. If you’re not feeling this pain, the information you wish to remember is not likely to stick.
On the other hand, if you’re trying to learn new negotiating techniques, or if you seek to develop programming skill, memorisation of this sort will be less useful to you.
[Recall] The Spacing Effect
The recall effect brings us conveniently to the next aspect of memory retention: the spacing effect.
The flip side of “you remember what you attempt to recall” is “you will forget what you don't attempt to recall”. The rate at which you forget is an exponential curve of decaying information; we call this the Forgetting Curve.
The spacing effect is a wonderful quirk of the forgetting curve: if you attempt to recall a piece of information right at the point where you are about to forget it, your brain will hold on to this memory for a period of time that is longer than the first forgetting curve. This holds true for every subsequent cycle of the forgetting curve — the third curve is longer than the second, the fourth is longer than the third, and so on.
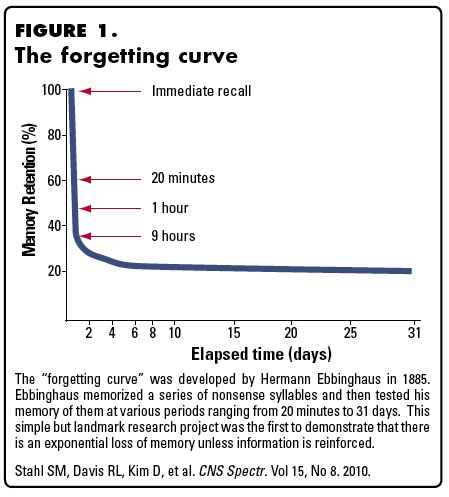
The catch, of course, is that you can’t remember what you are just about to forget; notwithstanding the fact that everyone's forgetting curve is different. The solution is to use software to calculate the exact point at which you are about to forget a piece of information. The good news is that there are a ton of reasonably priced options available to you: the most popular ones are probably Anki and SuperMemo — but go ahead and Google for others, you’re likely to find something that suits your tastes.
There are, however, several drawbacks to the technique: Gwern has compiled the best summary of spaced repetition research that exists on the internet, which I absolutely recommend that you read. In it, he covers the incredibly large and incredibly depressing body of evidence that explains why spaced repetition isn’t as popular as it should be. As it turns out, cramming works better for short-term studying, and spaced repetition isn’t as emotionally rewarding because it gives up strength of memory for duration of recall (you never feel as if you’ve ‘learnt something’, which is satisfying and thus important for habit-forming); this makes it difficult to maintain for long periods of time.
Be that as it may, it’s important to understand that the spaced repetition effect exists, and that you can use it to augment your ability to recall declarative pieces of knowledge.
[Recall] Short Term Memory Overload
I’ve alluded to the nature of short term memory earlier in this piece: that you are limited to 7±2 (or 4±1) chunks of information in short term memory, and that you should understand that the goal of learning is ‘effectively transfer what you’ve learnt from short term memory to long term memory’.
I argued that the exact number of chunks isn’t as important; the reason I say this is because the practical implication of this fact is much simpler: space your study sessions apart.
In order to prevent the overloading of short term memory, take little breaks after short, well-delineated studying sessions. An equally effective technique is to ‘take a break’ by switching up the subjects you’re studying, so that transference to long-term memory for the first subject may occur.
Here’s a helpful metaphor: imagine that short term memory is a small ‘staging’ area, one that serves as a loading bay to the infinite warehouse of your long term memory. Space in the loading bay is limited. You don’t want to overload it. So, split up your studying sessions to ensure that you load only what fits; programming educator Greg Wilson explicitly recommends that teachers plan lessons around 7±2 concepts, no more, no less.
Miller’s Magical Number may be a heuristic, but it appears to be a very effective one.
[Recall] The Visual/Linguistic effect
Here’s another brain quirk that educators have known for years: our brains process visual and linguistic information using two different subsystems. Presenting complementary information (e.g. pictures accompanied by words) causes the two streams of information to reinforce each other, increasing recall. This is effect is known as ‘dual coding’.
One important caveat is worth mentioning: the information must be complementary, not identical. Presenting the same information simultaneously in two different channels forces the brain to check the channels against each other, which nullifies the reinforcement effect (Mayer & Moreno, 2003).
The practical implication is to draw or label timelines, maps, family trees, or whatever else that seems appropriate to the material. A powerful variant of this technique is to draw a diagram without labels, only to come back later to label it, which serves as a double whammy of dual coding and retrieval practice. (Wilson, 2018)
Dual coding teases a possible use of the visual subsystem: what if we take the idea that our brains process visual information differently and use it to recall associated concepts? Good idea! This leads us to ...
[Recall] The Memory Palace Technique
The memory palace technique is the technique that memory champions use to memorise large strings of random numbers in memory competitions across the world.
To demonstrate this technique, I want you to remember your childhood home. Close your eyes and enter the front door. Look around the first room you see. The odds are good that you can remember each piece of furniture, the pillows on the couches and the decorations on the walls, whatever they may be.
Now, tell me the capitals of Russia, China, and Korea. Say each name out loud.
Now close your eyes again and imagine that you are riding a bike. If you don’t know how to ride a bike, imagine that you are swimming. If you don’t know how to swim, imagine that you are climbing up a flight of stairs. Bring to mind the embodied feeling of doing those activities.
Each of these exercises demonstrates a different form of recall. The first exercise is episodic memory. The second is declarative, and the third is procedural.
Notice how you might strain a little to retrieve declarative knowledge, but you don’t strain in the same way to retrieve the visual memory of your childhood home, nor the embodied memory of riding a bicycle.
The memory palace technique hijacks your episodic memory to store declarative knowledge. The technique itself is simple: place yourself back in that room you have visualised earlier. Now:
- Going clockwise from the entrance, focus your attention on each item you notice in the room. You may choose a table, or a series of large cushions on the floor, or a bunch of quirky statues that your mum keeps on the mantelpiece. Your goal is to memorise a specific sequence of objects in the room.
- Number those items, and repeatedly go through them in the exact same order.
- Have a list of objects you desire to memorise on hand. This could be a list of numbers, or a list of facts. For instance, if you are a medical student, you can have a list of disease symptoms in front of you.
- Go through the list and imagine each item placed in the location of each object that you’ve just listed, earlier.
I won’t go into detail here because there are tons of good resources on the internet for building memory palaces. A quick search on Youtube reveals a few hundred videos; this video by Ron White seems like a good place to start.
Why does the memory palace technique work so well? The reason it works is because it leverages the way our brains store episodic memories — that is, the exact methods with which your brain conjures up memories of your first home, your first kiss, or that time when you peed in the cinema. By imagining the placement of facts (disguised as objects) around a room you are already familiar with, you are essentially creating a new episodic memory, one that is much easier to pull up.
Since we are interested in memory retention techniques, the memory palace is worth knowing about, but it’s important to remember — again! — that the kind of memory it aids is the same as spaced repetition: you are merely encoding declarative knowledge for subsequent use.
The same effects we discussed earlier — retrieval practice, the forgetting curve — apply.
[Recognition] The Basis of Expertise
We’ve spent a lot of time so far on memory recall. It is time to talk a little about recognition as a tool for memory retrieval. First, consider the following list of questions:
- Is it possible to forget how to swim?
- Is it possible to forget how to drive a car?
- Is it possible to forget how to ride a bicycle?
The answer to all of these questions is ‘yes’, but the nature of forgetting with these skills is very different from the forgetfulness that we’ve just discussed. Episodic memories can fade if you suppress them. Declarative knowledge will vanish at an exponential decay — this is the Forgetting Curve we've discussed earlier. But procedural memory works very, very differently.
You can go for years without riding a bike, and then after a brief period of reacclimatisation (“Oh, I’m so rusty!” you exclaim) — go off riding in the mountains. The same is true with swimming and driving.
The reason procedural knowledge differs from episodic knowledge and declarative knowledge is because procedural knowledge is stored in a different part of your brain. One of the subsystems involved is known as implicit memory. It is the same subsystem that recognises faces: when you see someone you know walking into the room, you don’t consciously search your memory for the face in question — instead, the knowledge appears, unbidden, in your head.
(To be precise: facial recognition triggers first, followed quickly by snatches of episodic memory connected to the face. Name retrieval is a declarative knowledge retrieval process, and may come much later — especially if the person is someone you’ve not seen for years).
Riding a bicycle, driving a car, and swimming the breast stroke are forms of procedural knowledge, and as such exist as a collection of mental representations stored against a bank of objects in your implicit memory. When you ride a bike, your brain is quickly pulling up these chunks of implicit memory through pattern recognition, and ‘unfurling’ the mental representations associated with the recognised memory. (Klein, 1999)
As I’ve written about before, this model of expertise is known as Recognition-Primed Decision Making Model (RPD), and was mapped out in the 90s by a group of psychologists working for the US military. When an expert looks at a situation, the following cognitive processes trigger:
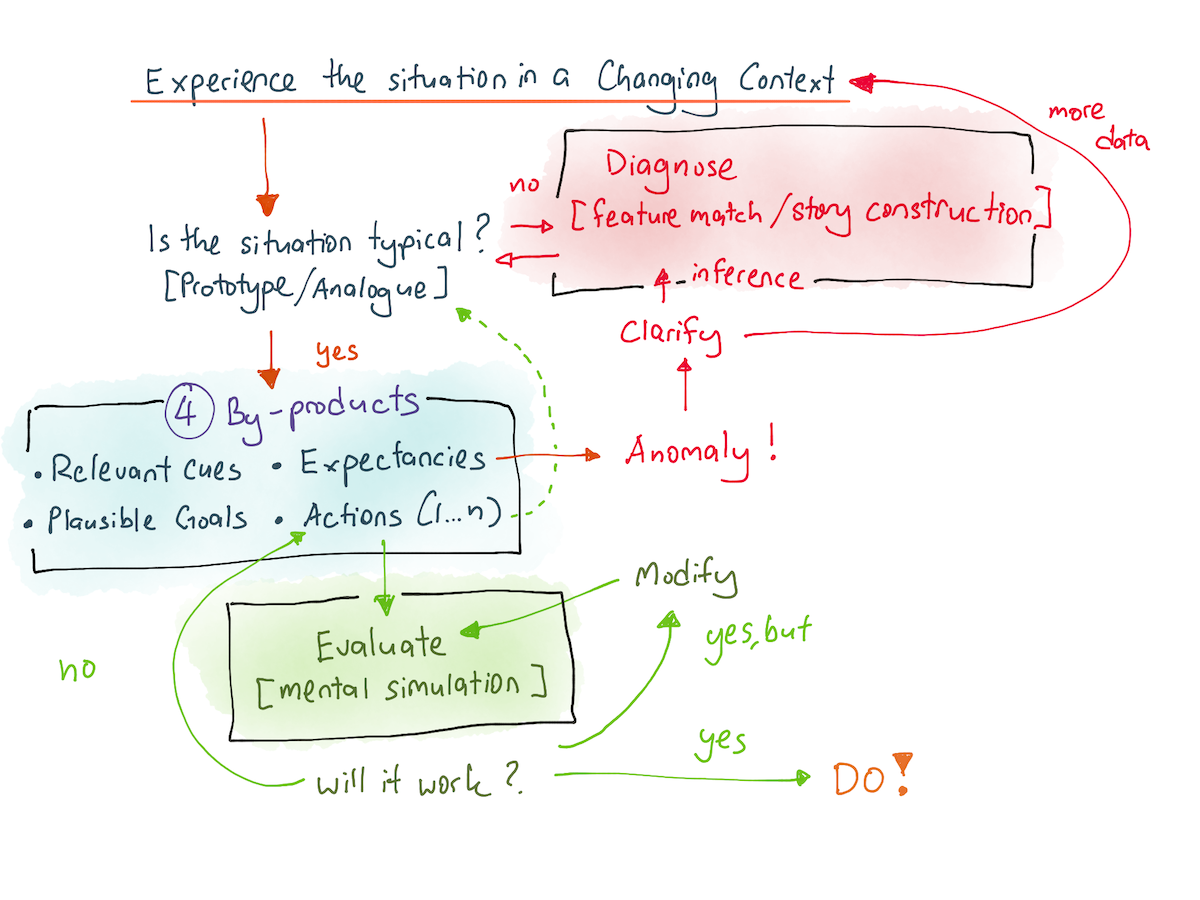
First, the expert pattern-matches against a bank of stored prototypes, or situations. We often refer to this as a practitioner’s ‘store of experience’. This recognition is an implicit memory operation, so it happens very rapidly — as quickly as facial recognition, in fact — and the memories that are stored here fade slower than typical pieces of declarative knowledge.
The four most important by-products that are generated by the recognition are:
- Relevant cues, that tell the brain what to focus on (e.g. imagine that you are turning at an intersection; you only look at certain things like your side mirrors, your turn signal, your clutch, and which gear you’re in; you ignore other signals like your speedometer and the song that’s playing on the radio).
- Plausible goals, ranked in priority and worked out as a result of prior experience.
- Expectancies, which are a series of expected things that should occur in such a situation. If violated, the expert gets a ‘bad feeling’; his brain recognises that this situation is atypical and switches back to pattern-recognition mode.
- And finally, an action script, which tells the expert the series of embodied actions to do or the series of decisions to make.
All forms of expertise function according to this framework. When Anders Ericsson writes about deliberate practice, what he’s really talking about is either expanding the implicit memory bank of recognised situations, or training the appropriate set of embodied actions attached to those recognised situations.
Chess grandmasters recognise an enormous variety of chess positions. But note that they do not memorise these positions using a spaced repetition system, or even a memory palace. Instead, they encode this knowledge through practice: they do exercises where they analyse old games, and attempt to predict what a grandmaster might do in a given position. If they get the move wrong, they return to their analysis and redo the move. Over the course of a given week, an aspiring chess champion goes through hundreds of such moves — usually with the aid of computer programs that serve historical chess positions on the fly.
You could argue that such exercises are a form of spaced repetition practice. After all, many chess position share similarities to other chess positions; the repeated exercise merely seeks to expose the chess player to every possible variation of each position. But the end-result can be rather different: unlike with spaced repetition, the goal is to develop tacit mental models of chess; the expert chess player is often unable to explain their decision making processes, and instead says something like “it felt like the right thing to do.”
This is implicit memory in action.
[Recognition] Encoding Memories Through Practice
RPD presents us with a different model for memory: if you want to improve your retention rate, one way to do so is to embed such things in procedural memory, to the point where it ceases to become something you can recall explicitly.
The put this differently, you remember by practicing a skill, instead of remembering by practicing recall.
As a software programmer, I don’t put programming language features into Anki. Instead, I find excuses to use those features in the day-to-day programming work that I do. (Or I construct side projects around those features as an excuse to use them, and implement those projects on nights and weekends). The language feature eventually vanishes from my conscious mind — instead, it is represented as a tacit mental model, internal to myself. In some cases, I am unable to explain it.
As a writer, I don’t memorise narrative techniques using spaced-repetition flash cards. Instead, I take each technique that I’m interested in using, and find an excuse to put them into my writing. Sometimes this works well, and sometimes it results in a mess. After a few attempts, the tool that I seek to learn eventually transforms into a tacit mental model — and vanishes from my conscious mind.
This is, in fact, exactly how I learnt to write — when I was 18, I spent a year working my way through Roy Peter Clark’s Writing Tools: 50 Essential Strategies for Every Writer, which was originally published as a series of blog posts on Poynter.org. I did not move on to the next chapter until I had successfully put to practice the technique from the previous chapter. It took me over eight months to finish everything. If you ask me today what those 50 tools are, I can only remember a handful. But when I flip through the pages of Clark’s book again, I realise that I have internalised so many of Clark’s tools that it is clear his approach is imprinted in everything that I write.
It’s been more than a decade since I read Clark’s book — and yet I have not forgotten; it has simply become a part of me. Such is the power of procedural memory.
Bringing It Together
Instead of describing my method of integrating the techniques above, I’ll present a series of learning scenarios and my approaches to them. Hopefully this gives you an idea of the heuristics that I’ve developed for myself, given what the research suggests.
My hope is that you will steal some of my ideas, or at least refine them for your own use. I do not pretend to know what works for you — after all, my needs are quite different from yours.
So here goes:
Former FBI hostage negotiator Chris Voss presents a handful of techniques to get what you want at work and in life in Never Split the Difference. Each chapter in the book presents a negotiating technique, along with examples from Voss’s rather violent career (and now more peaceful corporate consulting practice). How would you study Voss’s techniques and apply them to your life?
Voss attempts to teach procedural knowledge. This means that any attempt to memorise his techniques isn’t going to be as useful as internalising them through practice.
My approach to Voss’s book was to read the book chapter by chapter, only moving to the next chapter after I had put to practice the techniques suggested in the previous chapter. This averaged out to be around a chapter every two weeks. Thankfully, I was handling multiple clients for my company at the time, making it easy for me to practice Voss’s techniques on them (and in one case, I successfully played off one client department against another, buying us enough time to complete a project for the company in question).
I finished the book over a period of six months. I reach for Voss's techniques very naturally, today.
Andy Grove presents a framework for evaluating threats to one’s career in Only the Paranoid Survive. This framework should be applied irregularly, whenever an emerging technology, or emerging environmental change impacts one’s job.
Grove’s framework is somewhat procedural — but the problem is that you won’t get many opportunities to put the framework to practice in one’s career. My approach was to summarise the book in Ulysses, my writing software of choice (you may read the summary here) and then apply it to blockchain technology shortly after finishing, as an excuse to put the framework to practice.
Going forward, I’ll have to refer to my summary, which is still better than referring to the book. I fully intend to analyse emerging technologies through the lens of Grove’s framework; it provides some structure to otherwise formless change.
I do not see the need to memorise it. It’s simply not worth the effort.
The procrastination equation is an ‘equation’ the describes human motivation, originally developed by Piers Steel. Luke Muehlhauser has a fantastic blog post on how to use the equation to beat the underlying causes that lead to procrastination. I’ve used this blog post repeatedly over the past year, to some success.
This is different from Grove’s framework. I procrastinate quite a bit, and find myself reaching for the formula to analyse my emotional state once every two months or so. This is often enough to make referring to Muehlhauser’s article annoying, but irregular enough to make it difficult for me to commit the equation to memory via practice.
My solution? I created a memory palace of my old college dorm room and placed the four elements of the equation in my cupboard, work chair, bed, and bedside table respectively.
I would say that if I were a doctor, I would not hesitate to commit diagnostic criteria for common diseases to memory — perhaps using spaced repetition software. Doing so should free up my brain to learn the nuances of clinical practice … but more realistically it would help me survive the gauntlet that is medical residency.
Thankfully, however, I am not a doctor. In my current role, I have limited use for memory retention strategies; instead, I summarise books as an aid for reading comprehension, and to produce an artefact that I may refer to.
This may change as my career progresses.
In Sum
I think that many of us who are eager to improve our memory retention forget that the purpose of memory retention is often mastery. Memory retention strategies are universally useful if you have to score highly in an exam. But if you are a knowledge worker, and your goal is to build rare and valuable skills, you are better served by being strategic with your memory retention strategies.
For instance, as a programmer, I am able to code quickly because I hold a set of common APIs in my head. However, if I do not know the APIs that I need, I can quickly pull it up by searching the language documentation, or by Googling for a solution. In practice, most programmers are augmented with editors that suggest common language functions, making memorisation beyond that which you pick up through practice rather wasteful.
The key is to recognise that different forms of knowledge demand different learning strategies. Don’t be like the Medium writer who sees ‘spaced repetition’ and ‘programming language features’ and immediately concludes ‘oh, I can use spaced repetition to learn new programming languages more effectively!’ Such a person is not going to get very far … because, well, programming skill is not a form of declarative knowledge.
How do I know this? Because I was that idiot … once.
Don’t use screwdrivers to juice oranges. Use them for screws instead. Memory retention techniques have their place in one’s toolbox. Use them wisely.
Appendix
Author’s note, 20 June 2019: I’ve experimented with all the techniques covered in the above post. The only two techniques that I've had trouble with is a) spaced repetition and b) mind-mapping.
- Spaced repetition: I’ve had serious trouble with motivation over long stretches of doing SRS practice. As Gwern writes, spaced-repetition practice never gives you a cognitive reward at the end of a session. I should probably circle back to this practice, though, now that I know of BJ Fogg's trick of creating a ‘fake’ celebration at the end of a desired activity.
- Mind-mapping: I’ve not had good results from creating mind-maps, though I’ve found the concept map variant to be particularly useful for teaching. I think the takeaway here is that I was too eager to stuff everything into mind-maps, whereas I should've been more flexible — the dual coding technique for learning argues that the visual representation you use should fit the type of information you are working with. I've not used mind-maps seriously for more than a decade at this point, though — perhaps now would be a good time to return to it for practice.
Originally published , last updated .
This article is part of the Expertise Acceleration topic cluster. Read more from this topic here→



